Anthropic released Claude Sonnet 5 on June 30, 2026, and the early Sonnet 5 benchmarks tell a clear story: this is the closest a Sonnet-tier model has ever come to matching an Opus-tier flagship. Anthropic calls it the company’s most agentic Sonnet model yet, with performance close to Opus 4.8 that represents a notable improvement over Sonnet 4.6. For developers, SaaS buyers, and enterprises trying to decide whether to migrate, that positioning matters more than any single leaderboard number.
Sonnet 5 isn’t a bigger model wearing a new badge. It’s built as a hybrid reasoning model offering fast, capable intelligence for real-time agents and high-volume work, with a 1M-token context window. What changed since Sonnet 4.6 is agentic follow-through: early testers reported the model finishing multi-step tasks that previous Sonnets would abandon partway through, and checking its own work without being asked.
First impression of Claude Sonnet 5
This model appears to be strongly optimized for performance, aligning with Anthropic’s early messaging around capability and reliability. That emphasis is reflected in how consistently it seeks accurate, well-reasoned answers, even in situations where no objectively correct answer exists.
Its reasoning style feels deliberate and highly goal-driven. Rather than sitting with ambiguity or unresolved contradictions—as seen with Opus 4.8—it actively works to reconcile inconsistencies and move toward a coherent conclusion.
When handling existential or philosophical prompts, the model can still offer meaningful pushback, though in a more restrained and straightforward manner. Compared with Opus 4.8, its responses feel less nuanced in how it challenges assumptions.
Another noticeable trait is its tendency to interpret even mild user prompts as problems to solve or challenges to overcome. This gives it a more intense, less relaxed interaction style. Because of that, it may perform best in collaborative settings where the conversation feels like working alongside a capable colleague, rather than in scenarios that unintentionally trigger a need to prove itself.
Quick Summary
| Best for | Agentic coding, multi-step automation, high-volume production workloads |
| Biggest strength | Terminal and tool-use reliability approaching Opus-level at Sonnet pricing |
| Biggest weakness | Still trails Opus 4.8 on the hardest reasoning and cyber-offense tasks |
| Worth trying? | Yes, especially during the introductory pricing window through August 31, 2026 |
First Impressions
Model behavior: The standout change isn’t raw intelligence, it’s persistence. Early access partners consistently described Sonnet 5 finishing complex tasks where previous Sonnet models would stop short, checking its own output without being explicitly asked, and doing this agentic work at an attractive price point. Anthropic
Speed and responsiveness: Sonnet 5 keeps the hybrid design of earlier Sonnets, answering instantly for simple queries and switching into extended thinking for harder ones. Anthropic gives API users granular control over that effort level, so latency-sensitive apps aren’t forced to pay for reasoning they don’t need.
Coding quality: In practice, this is where the upgrade is most visible. Sonnet 5 is built to navigate real codebases, land multi-file changes, and carry debugging and refactoring tasks through to completion, producing cleaner and more maintainable code with less oversight. For teams running CI review bots, test generation pipelines, or batch refactors, that’s a direct efficiency gain, not a benchmark abstraction.
Real-world usability: The model can hold a plan across multiple stages, track what’s been done and what remains, and resolve issues with fewer correction rounds, which translates into more predictable behavior at production scale. That’s the difference that matters for anyone running unattended agent loops.
One caveat worth flagging honestly: this is Anthropic’s own characterization, echoed by early partners. Independent, large-sample usage data is still thin at launch.
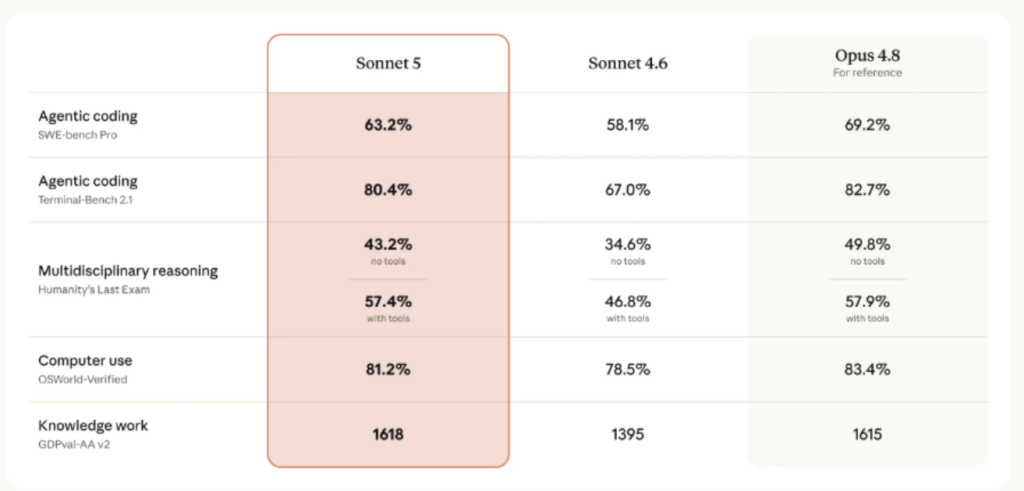
Sonnet 5 Benchmarks
Here’s how Sonnet 5 stacks up against its predecessor and the current frontier field. Figures below combine Anthropic’s own reported numbers with independently tracked comparisons; where sources diverge (a known issue in LLM benchmarking, discussed below), that’s noted.
| Benchmark | Claude Sonnet 5 | Claude Sonnet 4.6 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
| SWE-bench Verified (coding) | 72.7%¹ | 62.3%¹ | 79.4%¹ | ~88.7% (vendor-reported) | 80.6% |
| Terminal-bench (agentic coding) | 76.1%¹ | 55.4%¹ | — | 82.7% (Terminal-Bench 2.0) | — |
| GPQA Diamond (reasoning) | Not yet independently benchmarked | ~89–90% | High-80s range | ~83–85% | 94.3% |
| Context window | 1M tokens | 1M tokens (beta) | 1M tokens | 400K tokens | 1M–2M tokens |
| Max output tokens | 128K | — | — | — | — |
What these numbers mean in practice: The Terminal-bench jump of roughly 20 points is the headline figure for agent builders, since it measures multi-step task completion in real terminal environments — exactly the workload Sonnet 5 is built for. A 10-point SWE-bench gain generally means fewer human interventions per PR, not a dramatically “smarter” model on any single query.
Treat cross-vendor benchmark tables with some skepticism. Different labs run different evaluation harnesses, and the spread between a vendor’s own tuned scaffold and a standardized third-party harness can swing results by 15–20 points on the same model. Weight GPQA Diamond, real production usage reports, and your own task-specific tests more heavily than any single leaderboard screenshot.
On reasoning-heavy science benchmarks specifically, Gemini 3.1 Pro currently holds the top published score, while GPT-5.5 leads on raw agentic coding throughput in Terminal-Bench 2.0. Sonnet 5’s edge is elsewhere: tool-use reliability, lower hallucination rates, and cost-to-performance ratio for sustained agent work.
Pricing
Sonnet 5 launches at an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026, after which standard pricing of $3 per million input tokens and $15 per million output tokens takes effect.
| Access type | Details |
| Claude.ai Free/Pro | Default model, chat access via web, iOS, Android |
| Max, Team, Enterprise | Available alongside Opus 4.8 |
| API (introductory, through Aug 31, 2026) | $2/MTok input, $10/MTok output |
| API (standard, from Sept 1, 2026) | $3/MTok input, $15/MTok output |
| Batch API | 50% discount on input and output |
| Prompt caching | Up to 90% savings on cached input |
| Context window | 1M tokens included at standard pricing, no surcharge |
One important detail for anyone budgeting migration: Sonnet 5 uses a new tokenizer that produces roughly 30% more tokens for the same input text than Sonnet 4.6, so per-request cost can shift even though per-token pricing hasn’t. Anthropic set the introductory rate specifically to offset that, but it’s worth re-measuring your actual prompts before committing to production volume.
Value for money: At $2/$10, Sonnet 5 undercuts Opus 4.8’s $5/$25 per-million pricing by a wide margin, giving Sonnet 5 a clear price advantage for high-volume agent workloads. It’s the obvious default for teams that don’t need Opus-level ceiling performance on every request.
Strengths & Limitations
Strengths:
- Strong, near-Opus coding performance at a fraction of Opus pricing
- 1M-token context window included by default, no separate long-context tier
- Reported lower hallucination and sycophancy rates versus Sonnet 4.6
- Reliable multi-step tool use and agent follow-through
- Cyber safeguards enabled by default for dual-use risk mitigation
Limitations:
- Still trails Opus 4.8 on the hardest reasoning and cyber-offense benchmarks
- No Priority Tier support at launch, unlike Sonnet 4.6
- New tokenizer inflates token counts, requiring budget re-calibration
- Benchmark comparisons across vendors use inconsistent harnesses, so headline numbers need context
- Not the strongest option for pure scientific/graduate-level reasoning (Gemini 3.1 Pro leads there)
Final Verdict
Sonnet 5 is worth using, particularly right now. The introductory pricing window makes it one of the best cost-to-capability ratios currently available from any major lab, and the agentic reliability gains are the kind of improvement that shows up in fewer failed pipeline runs, not just leaderboard bragging rights.
Choose Sonnet 5 if: you’re running production coding agents, high-volume content or document workflows, or customer-facing automation where consistency matters more than peak reasoning power.
Consider alternatives if: you need the absolute ceiling on graduate-level scientific reasoning (Gemini 3.1 Pro), the fastest raw agentic coding throughput regardless of cost (GPT-5.5), or genuinely frontier-tier reasoning where budget isn’t a constraint (Claude Opus 4.8).
Frequently Asked Questions
How good are Sonnet 5 benchmarks?
Strong for a mid-tier model — near-Opus performance on coding and agentic tasks, with a notable jump on Terminal-bench specifically, though it still trails Opus 4.8 and top competitors on pure scientific reasoning.
Is Sonnet 5 better than GPT-5?
It depends on the task. Sonnet 5 is more cost-efficient and strong on sustained agentic coding; GPT-5.5 currently leads on raw Terminal-Bench 2.0 throughput and vendor-reported SWE-bench scores, at a higher price point.
How much does Claude Sonnet 5 cost?
$2 per million input tokens and $10 per million output tokens through August 31, 2026, rising to $3/$15 per million tokens afterward.
Is Sonnet 5 good for coding?
Yes — it’s positioned as Anthropic’s strongest coding-focused Sonnet yet, built for multi-file changes, debugging, and sustained refactoring with less human oversight.
Is Sonnet 5 worth it for businesses?
For high-volume, cost-sensitive agentic workloads, yes. For the highest-stakes reasoning tasks, Opus 4.8 remains the safer choice.
Does Sonnet 5 have a large context window?
Yes, 1M tokens by default at standard pricing, with a 128K max output limit.
Is Sonnet 5 available for free?
Yes, it’s the default model for Claude.ai Free and Pro plan users.
What’s the biggest change from Sonnet 4.6?
Agentic persistence and tool-use reliability — the model completes more multi-step tasks end-to-end without stalling or requiring correction.